
Introduzione
Il crawling, processo automatico con cui i motori di ricerca come Google scoprono contenuti web è il fondamento della visibilità online. Questo meccanismo di esplorazione continua alimenta gli indici di ricerca, permettendo agli utenti di trovare pagine, video e immagini. Lungi dall’essere statico, il crawling si è evoluto in un sistema complesso che include scoperta, scansione e rendering, affrontando oggi sfide cruciali legate all’intelligenza artificiale generativa, all’efficienza delle risorse (dynamic crawl budgeting) e alla sostenibilità economica del web aperto. Comprendere il suo funzionamento è essenziale per chiunque operi nel digitale.
-
Cos’è il crawling e come funziona il ciclo di scoperta
Il crawling è il primo passo: i crawler (o spider) seguono link e Sitemap per trovare contenuti. Gli URL vengono accodati (crawling queue), scansionati (rispettando il robots.txt) e infine elaborati, con un processo di rendering per i contenuti JavaScript, permettendo ai motori di ricerca di vedere il web.
-
La biforcazione del crawling: IA vs. indicizzazione
L’avvento dell’IA ha diviso il crawling di bot come Googlebot per l’indicizzazione tradizionale da quelli come Google-Extended utilizzati per addestrare modelli quali Gemini. Questa separazione gestibile via robots.txt offre ai publisher controllo sull’uso dei loro contenuti per l’IA, ponendo però un dilemma strategico sulla visibilità futura nelle ricerche conversazionali.
-
Crawl budget dinamico: la meritocrazia delle risorse
Il crawl budget non è più fisso ma dinamico (dynamic crawl budgeting), influenzato quotidianamente dalla salute tecnica del sito (Core Web Vitals, errori server). Un quality pre-check valuta il Return On Investment (ROI) della scansione, premiando siti performanti con più risorse e penalizzando quelli lenti o con errori, rendendo la SEO tecnica cruciale per la scopribilità.
-
La crisi del traffico estrattivo e le difese dei publisher
L’aumento esponenziale dei bot Al puramente estrattivi (che non portano traffico di riferimento) ha creato una crisi economica, imponendo costi infrastrutturali ai siti. Questo ha spinto all’adozione di metriche come il crawl-to-refer ratio e a tecniche di difesa avanzate (rate limiting, WAF) per bloccare traffico parassita.
-
Efficienza e controllo nell’era del crawling moderno
Una sintesi delle trasformazioni chiave del crawling, che evidenzia come l’efficienza tecnica (dynamic crawl budget), il controllo sull’uso dei dati per l’IA (Google-Extended) e la gestione strategica del traffico dei bot siano diventati pilastri fondamentali per garantire la visibilità e la sostenibilità economica nel nuovo ecosistema della ricerca web.
Cos’è il crawling e come funziona
Il crawling è il processo di scoperta automatizzato con cui i motori di ricerca analizzano il web per trovare contenuti nuovi o aggiornati. Questo meccanismo rappresenta il fondamento su cui si basa l’intera ricerca web, agendo come un sistema di esplorazione continuo che alimenta i vasti indici da cui vengono estratti i risultati. Il crawling è un ciclo operativo complesso che include la scoperta, l’accodamento, la scansione e il rendering delle pagine web, determinando la capacità stessa di un contenuto di essere visibile online. Senza questa fase preliminare, i motori di ricerca non potrebbero scoprire l’esistenza di nuove pagine, video o immagini da mostrare agli utenti.
Definizione di crawling: il processo di scoperta del Web
Il crawling è il primo passo fondamentale che precede l’indicizzazione e il posizionamento dei contenuti nei risultati di ricerca. La sua funzione non è quella di valutare o classificare una pagina, ma semplicemente di vederla e acquisirne il contenuto grezzo. Per questo motivo, può essere definito come il motore di scoperta del web: un sistema instancabile che mappa la struttura di Internet per renderla accessibile e interrogabile. La gestione di questo processo avviene attraverso protocolli standard che permettono ai proprietari dei siti di comunicare con i crawler.
I Protagonisti: chi sono i crawler (o spider)
I protagonisti del crawling sono programmi software automatizzati noti come crawler, spider o bot. Questi agenti digitali navigano il web seguendo sistematicamente i link da una pagina all’altra per costruire e aggiornare costantemente la mappa dei contenuti di un motore di ricerca. Ogni motore di ricerca gestisce una propria flotta di crawler, ciascuno identificato da una stringa univoca chiamata user-agent.
Tra i più noti figurano:
- Googlebot Il crawler principale di Google con diverse varianti per la ricerca desktop, mobile e per altri servizi specifici come immagini e news;
- Bingbot L’equivalente di Microsoft per il motore di ricerca Bing.
- YandexBot Il crawler del motore di ricerca russo Yandex.
È importante notare che non tutti i bot che visitano un sito sono crawler di motori di ricerca; esistono innumerevoli altri bot con scopi differenti, dall’analisi dei dati all’addestramento di modelli di intelligenza artificiale.
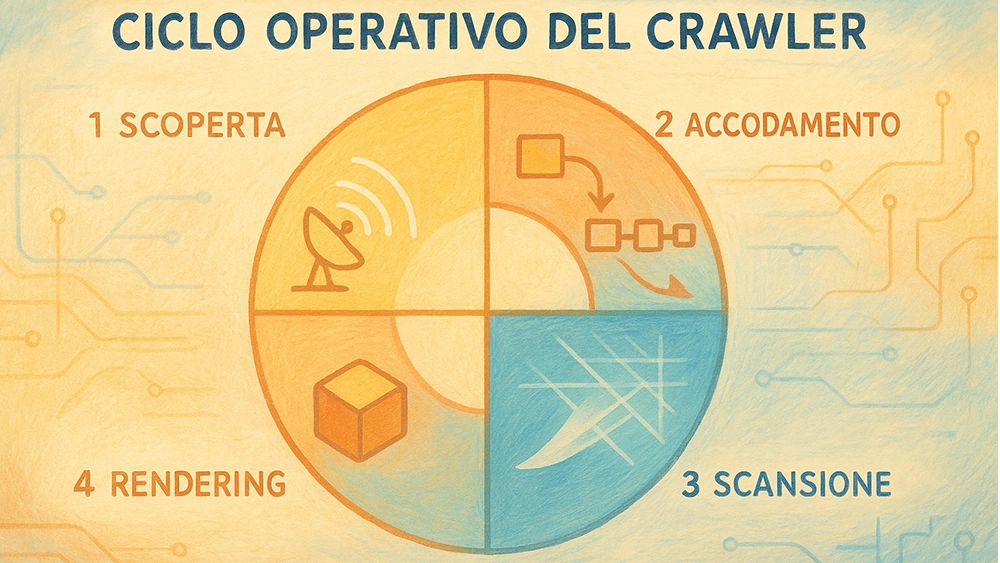
Il Ciclo operativo del crawler
Il lavoro di un crawler non è casuale, ma segue un ciclo operativo ben definito e ottimizzato per gestire l’immensa scala del web.
-
Fase di scoperta
Il processo inizia con un elenco di URL noti, generato dalle precedenti sessioni di crawling. Da questo punto di partenza, i crawler scoprono nuove pagine principalmente in due modi: seguendo i link (tag <a>) presenti nelle pagine che già conoscono e analizzando i file Sitemap forniti dai proprietari dei siti. Le sitemap sono particolarmente importanti perché possono rivelare pagine che potrebbero non essere facilmente scopribili attraverso la sola navigazione dei link;
-
Fase di accodamento (crawling queue)
Tutti gli URL scoperti, sia nuovi che da rivisitare vengono inseriti in una gigantesca coda di prioritizzazione nota come crawling queue. L’ordine in cui le pagine verranno scansionate dipende da numerosi fattori, tra cui l’autorevolezza del sito, la frequenza con cui i suoi contenuti vengono aggiornati e l’importanza della singola pagina. I motori di ricerca applicano algoritmi complessi per gestire questa coda in modo efficiente;
-
Fase di scansione (fetching)
Quando un URL arriva in cima alla coda, il crawler effettua una richiesta HTTP al server che ospita la pagina per scaricarne il contenuto. Prima di eseguire questa operazione, il crawler consulta il file robots.txt del sito, un protocollo che fornisce direttive su quali parti del sito possono essere scansionate e quali no. Se l’accesso è consentito, il crawler scarica il codice HTML grezzo della pagina;
-
Fase di elaborazione e rendering
Una volta ottenuto l’HTML, il crawler ne analizza il contenuto per estrarre informazioni utili, prima fra tutte la lista dei link presenti, che andranno ad alimentare nuovamente la fase di scoperta. Tuttavia, per i siti web moderni che utilizzano in modo intensivo JavaScript, la sola analisi dell’HTML non è sufficiente. Per questo, le pagine vengono messe in una seconda coda per il rendering: un processo computazionalmente più costoso in cui un browser headless esegue il JavaScript per costruire la pagina finale (DOM), rendendo visibili anche i contenuti e i link generati dinamicamente.
La grande biforcazione del crawling nell’era dell’IA
L’ascesa pervasiva dell’intelligenza artificiale generativa ha segnato una svolta fondamentale nel mondo della scansione web. Si è trattato di una vera e propria ristrutturazione dei principi di scoperta dei contenuti, che ha portato a una biforcazione del crawling in due percorsi distinti e gestibili separatamente: uno per la tradizionale indicizzazione e uno per l’addestramento dei modelli di IA. Questa separazione è una risposta diretta alle nuove pressioni tecniche ed economiche imposte da un ecosistema digitale radicalmente trasformato.
L’Avvento di Google-Extended per l’addestramento dell’IA
La novità più significativa è stata l’introduzione da parte di Google di Google-Extended. Questo user-agent è stato designato specificamente per il crawling di contenuti destinati all’addestramento dei suoi modelli di IA generativa, come Gemini e le API di Vertex Al. Per la prima volta, è stata creata una distinzione formale e tecnicamente applicabile tra il crawling finalizzato all’indicizzazione per la ricerca, gestito dal collaudato Googlebot, e la raccolta dati su larga scala per i Grandi Modelli Linguistici (LLM). Questa mossa ha fornito ai proprietari di siti web un livello di controllo senza precedenti.
II Controllo granulare tramite robots.txt
Grazie a questa distinzione, i publisher possono esercitare un controllo granulare sull’utilizzo dei propri contenuti. Utilizzando una semplice direttiva nel file robots.txt, è possibile negare il consenso all’uso dei contenuti per l’addestramento dell’IA. Per bloccare un crawler dedicato all’IA è sufficiente aggiungere la seguente regola, per esempio per bloccare il bot di Google:
User-agent: Google-Extended Disallow: /
Questa regola impedisce a Google-Extended di accedere al sito, lasciando inalterata la capacità di Googlebot di scansionare e indicizzare le pagine per la ricerca tradizionale. Questa evoluzione rappresenta la modifica più importante al protocollo robots.txt da molti anni, offrendo uno strumento ufficiale per gestire l’accesso ai contenuti nell’era dell’IA.
Il dilemma strategico dei publisher
L’introduzione dei bot IA ha posto ogni editore di fronte a una decisione strategica cruciale, con un trade-off significativo. Da un lato, bloccare questo tipo di crawler protegge la proprietà intellettuale, previene la potenziale cannibalizzazione del traffico da parte di risposte Al che rendono superflua la visita al sito originale e mantiene un pieno controllo editoriale. Dall’altro, è una che scelta potrebbe precludere la visibilità nelle funzionalità di ricerca basate sull’IA. Man mano che la ricerca si evolve verso interfacce più conversazionali, i contenuti non inclusi nei set di addestramento potrebbero essere di fatto esclusi da queste nuove forme di scoperta. La decisione di consentire o negare l’accesso ai crawler per l’IA è diventata quindi un elemento centrale della strategia di visibilità a lungo termine.
La meritocrazia delle risorse: crawl budget dinamico e quality pre-check
Parallelamente alla biforcazione del crawling, i motori di ricerca hanno formalizzato un cambiamento radicale nella filosofia di allocazione delle risorse di scansione, trasformando il crawling da un diritto acquisito a un privilegio guadagnato. È stato implementato un sistema di dynamic crawl budgeting, dove il budget di scansione non è più un valore semi-statico, ma una risorsa che varia quotidianamente in base a segnali di performance e qualità. Questo approccio — strettamente legato a un meccanismo di quality pre-check — costringe i motori di ricerca a trattare la scansione come un’operazione con un proprio ROI, premiando i siti che offrono un valore maggiore.
Dal diritto al privilegio: come funziona il crawl budget dinamico
Il crawl budget dinamico lega direttamente la quantità di attenzione che un sito riceve dai bot alla sua salute tecnica e alla qualità percepita. Prima di impegnare le costose risorse necessarie per una scansione e un rendering completi, i sistemi eseguono una valutazione preliminare (il quality pre-check) per decidere se l’investimento è proficuo. I siti veloci, affidabili e di alta qualità offrono un ROI più elevato in termini di contenuti di valore da aggiungere all’indice e vengono quindi premiati con un crawl budget più generoso. Al contrario, i problemi tecnici e la bassa qualità segnalano scarsa salute, portando a una progressiva riduzione delle scansioni future.

Il ruolo dei Core Web Vitals e della SEO tecnica
La salute tecnica di un sito, misurata in modo prominente dai Core Web Vitals, è diventata un fattore che influenza direttamente la frequenza e la profondità della scansione. Fattori come i tempi di risposta del server (TTFB), i punteggi dei Core Web Vitals, la frequenza di errori (come 5xx) e la presenza di link rotti impattano quotidianamente il numero di pagine che un crawler tenterà di scansionare.
Di conseguenza, la SEO tecnica ha assunto un’importanza strategica ancora maggiore: non è più solo una leva per migliorare il posizionamento, ma un prerequisito fondamentale per garantire che i contenuti vengano scoperti e indicizzati in modo efficiente. I siti con scarse performance rischiano di entrare in un circolo vizioso, vedendo il loro crawl budget ridursi, il che porta a un’indicizzazione più lenta e incompleta.
Ottimizzazione del crawl budget come disciplina continua
Per i team SEO questa evoluzione implica che l’ottimizzazione tecnica è diventata una disciplina continua e proattiva. Il monitoraggio costante dei log del server, un tempo considerata un’attività avanzata diventa uno strumento cruciale per comprendere come i crawler interagiscono con il sito, identificare le aree di spreco del crawl budget e ottimizzare l’allocazione delle risorse.. Un’attenta analisi dei log del server permette di identificare colli di bottiglia e opportunità di miglioramento per massimizzare l’efficienza della scansione.
La crisi del traffico estrattivo: L’impatto economico dei bot Al
Il terzo pilastro del crawling moderno è l’esplosione quantitativa del traffico generato dai bot di intelligenza artificiale. Questo fenomeno rappresenta una vera e propria crisi infrastrutturale ed economica per i publisher, in quanto altera il modello di business che ha sostenuto il web aperto per decenni. Il traffico generato dai bot di IA è cresciuto esponenzialmente, guidato da crawler di Meta, Google e OpenAl, che da soli sono arrivati a rappresentare quasi l’80% di tutto il traffico di bot Al.
L’asimmetria del valore: Il concetto di ‘Crawl-to-Refer Ratio’
A differenza dei crawler di ricerca tradizionali che operano in un ecosistema simbiotico di scoperta e riferimento, molti nuovi training crawlers sono puramente estrattivi. Spesso aggressivi, ignorano le direttive robots.txt e consumano enormi quantità di banda senza fornire un valore di ritorno proporzionale in termini di traffico. Questa asimmetria ha portato all’introduzione di un nuovo parametro di valutazione: il Crawl-to-Refer Ratio, che misura il rapporto tra il numero di scansioni ricevute da una piattaforma Al e il numero di visitatori che essa riferisce al sito di origine. Per alcune piattaforme, questo rapporto ha raggiunto livelli drammaticamente sbilanciati, con picchi di 70.900 scansioni per ogni singolo visitatore inviato.
I Costi nascosti: banda e risorse server
Questa dinamica ha messo a dura prova le infrastrutture dei publisher. Il traffico parassita impone costi significativi in termini di banda e risorse server, costringendo di fatto i proprietari dei siti a sovvenzionare lo sviluppo di tecnologie che minacciano i loro stessi modelli di business. L’impatto economico di un traffico che estrae valore senza generare un ritorno ha innescato un acceso dibattito sulla sostenibilità del web aperto, spingendo l’intero settore a reagire.
Tecniche di difesa e blocco avanzato dei bot
La crisi generata ha spinto il settore a cercare soluzioni di blocco e controllo dei bot più sofisticate. La semplice direttiva robots.txt si è rivelata insufficiente contro i crawler non conformi, rendendo necessaria l’adozione di strategie di difesa più attive. Tecniche come il rate limiting (limitazione della frequenza delle richieste) e il blocco di interi range di indirizzi IP sono diventate pratiche comuni. Per una protezione più robusta molti si sono rivolti a soluzioni di bot management sofisticate, come i Web Application Firewall (WAF), in grado di identificare e bloccare il traffico anomalo prima che raggiunga il server di origine.
Innovazioni tecnologiche nella gestione del crawling
I motori di ricerca hanno introdotto significative innovazioni per affrontare la crescente complessità del web. L’intelligenza artificiale è emersa come lo strumento chiave per ottimizzare l’allocazione delle risorse, mentre le decisioni sull’adozione di nuove tecnologie infrastrutturali hanno rivelato un complesso equilibrio tra i benefici per l’ecosistema e i costi operativi su larga scala.
Il rendering potenziato dall’IA e il ‘rendering budget’
L’innovazione più profonda risiede nell’applicazione dell’intelligenza artificiale alla gestione del processo di crawling e rendering. I motori di ricerca utilizzano modelli di machine learning per decidere come e quando scansionare i contenuti, specialmente per le complesse Single Page Applications (SPA) basate su JavaScript. Invece di accodare tutte le pagine per il rendering in modo indiscriminato, i sistemi ora allocano un rendering budget ottimizzato. La priorità viene assegnata alle URL che sulla base di dati storici e segnali di engagement hanno maggiori probabilità di essere importanti per gli utenti. Una fonte primaria per questa prioritizzazione sono le metriche reali provenienti dal Chrome User Experience Report (CrUX). Di conseguenza, l’esperienza utente e le performance sono input diretti che determinano la velocità di scansione e rendering.
II Rendering ibrido (SSR + CSR) come best practice
Nonostante i notevoli progressi nel rendering lato client da parte di Google, la best practice raccomandata per siti complessi o critici per il business rimane strategica. L’approccio più sicuro e robusto è il rendering ibrido (SSR + CSR), o il rendering server-side (SSR).
Queste metodologie garantiscono che i contenuti e i metadati essenziali — come titoli, descrizioni e link canonici — siano presenti nell’HTML iniziale inviato dal server. Questo rende il contenuto immediatamente accessibile al crawler, eliminando le incertezze e i potenziali punti di fallimento legati a un’esecuzione JavaScript puramente lato client.
Adozione di HTTP/2 e il ritardo su HTTP/3
Sul fronte dell’infrastruttura di rete, Googlebot ha raggiunto la piena maturità nel supporto del protocollo HTTP/2 per circa la metà delle URL scansionate, scegliendo di utilizzarlo quando porta a un significativo risparmio di risorse. Tuttavia, esiste una notevole discrepanza per quanto riguarda il protocollo HTTP/3. Nonostante i suoi vantaggi e la crescente adozione, il supporto di Googlebot a HTTP/3 è ancora mancante, probabilmente a causa dell’elevato overhead della CPU e dei costi infrastrutturali su larga scala. Questa situazione rivela una tensione tra le raccomandazioni pubbliche di Google (ottimizzare le performance) e l’economia della sua stessa infrastruttura, che per ora non giustifica un investimento così massiccio, preferendo ottimizzazioni software basate su IA.
| Protocollo | Vantaggi Chiave | Supporto Googlebot |
|---|---|---|
| HTTP/2 | Multiplexing, compressione header | Sì (maturo) |
| HTTP/3 | Basato su QUIC/UDP, latenza ridotta, no head-of-line blocking | No (supporto futuro) |
Il futuro del crawling: sostenibilità e sfide emergenti
Le più recenti trasformazioni hanno portato alla luce una serie di dibattiti e sfide strategiche che stanno plasmando il futuro del crawling e del web. Le discussioni riguardano questioni fondamentali di etica, sostenibilità economica e sicurezza. La corsa ai dati per l’addestramento dell’IA, la crescente consapevolezza dell’impatto ambientale delle operazioni digitali e l’evoluzione delle tecniche di evasione hanno creato un campo di scontro complesso per tutti gli attori dell’ecosistema.
‘Green crawling’: sostenibilità ambientale ed efficienza
Il concetto di crawling sostenibile sta emergendo con una duplice dimensione. La prima è la sostenibilità ambientale dei data center, che ha spinto grandi player digitali a investire massicciamente in efficienza energetica e approvvigionamento di energia pulita. La seconda è la riduzione degli sprechi computazionali durante la scansione, con iniziative che mirano a rendere il crawling più efficiente, informando proattivamente i bot quando i contenuti sono cambiati. Questi sistemi riducono drasticamente le scansioni superflue, portando a minori costi per i publisher e a un minor consumo energetico per i crawler. In questo contesto, l’efficienza del crawling è diventata un punto di convergenza tra obiettivi SEO, finanziari e ambientali.
L’escalation delle tecniche di evasione e difesa
La crescente pressione sui dati ha alimentato una sofisticata corsa tra tecnologie di evasione e di difesa. Da un lato, sono emersi servizi commerciali di Cloaking-as-a-Service (CaaS) che utilizzano l’IA e tecniche avanzate come il fingerprinting JavaScript per servire contenuti malevoli agli utenti, nascondendoli ai bot di sicurezza. Dall’altro lato, in risposta all’aggressività dei crawler Al i publisher stanno adottando tecniche di blocco sempre più avanzate. Oltre a metodi di base come il rate limiting, si sono diffuse soluzioni ingegnose come gli honeypots (trappole invisibili per identificare i bot) e l’analisi comportamentale per distinguere con precisione gli esseri umani dai programmi automatici. La distinzione tra bot buoni (crawler di ricerca), cattivi (scraper malevoli) e grigi (crawler Al) è sempre più difficile, richiedendo soluzioni di bot management sofisticate.
Conclusione
Il crawling, pur rimanendo il meccanismo fondante per la scoperta dei contenuti web da parte dei motori di ricerca come Google ha subito una trasformazione radicale. L’analisi del suo ciclo operativo – dalla scoperta all’elaborazione e rendering – rivela un sistema non più monolitico, ma profondamente influenzato dall’ascesa dell’intelligenza artificiale generativa e dalle crescenti pressioni economiche sull’ecosistema digitale. La biforcazione tra crawling per l’indicizzazione (Googlebot) e per l’addestramento Al (Google-Extended) gestibile tramite robots.txt rappresenta una svolta che impone scelte strategiche cruciali ai publisher riguardo al controllo e alla visibilità futura dei propri contenuti.
Parallelamente, l’introduzione del crawl budget dinamico ha instaurato una meritocrazia delle risorse, dove la salute tecnica del sito (influenzata dai Core Web Vitals e dalla SEO tecnica) determina direttamente l’attenzione ricevuta dai crawler. Questo rende l’ottimizzazione on-site una disciplina continua e fondamentale per la scopribilità. A complicare ulteriormente il quadro è la crisi del traffico estrattivo causata dall’aumento esponenziale di bot Al che consumano risorse senza fornire traffico di riferimento proporzionale, spingendo i publisher ad adottare metriche come il crawl-to-refer ratio e sofisticate tecniche di difesa.
In definitiva, il crawling moderno non si limita a essere un processo tecnico di scoperta, ma è un complesso agone strategico dove efficienza tecnica, controllo sull’uso dei dati per l’IA, sostenibilità economica e innovazioni continue come il rendering potenziato dall’IA e le future sfide del green crawling – si intrecciano richiedendo un adattamento costante e proattivo da parte di tutti gli attori del web per garantire visibilità e sopravvivenza. La gestione strategica del crawling è diventata – a tutti gli effetti – un pilastro irrinunciabile per operare con successo nell’ecosistema digitale contemporaneo.